STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning
Using LLMs for generating rationale for questions via bootstrapping
Introduction
Generating a step-by-step “chain-of-thought rationale” for solving complex reasoning problems has been shown to improve the Large Language Model’s (LLM’s) performance on the task
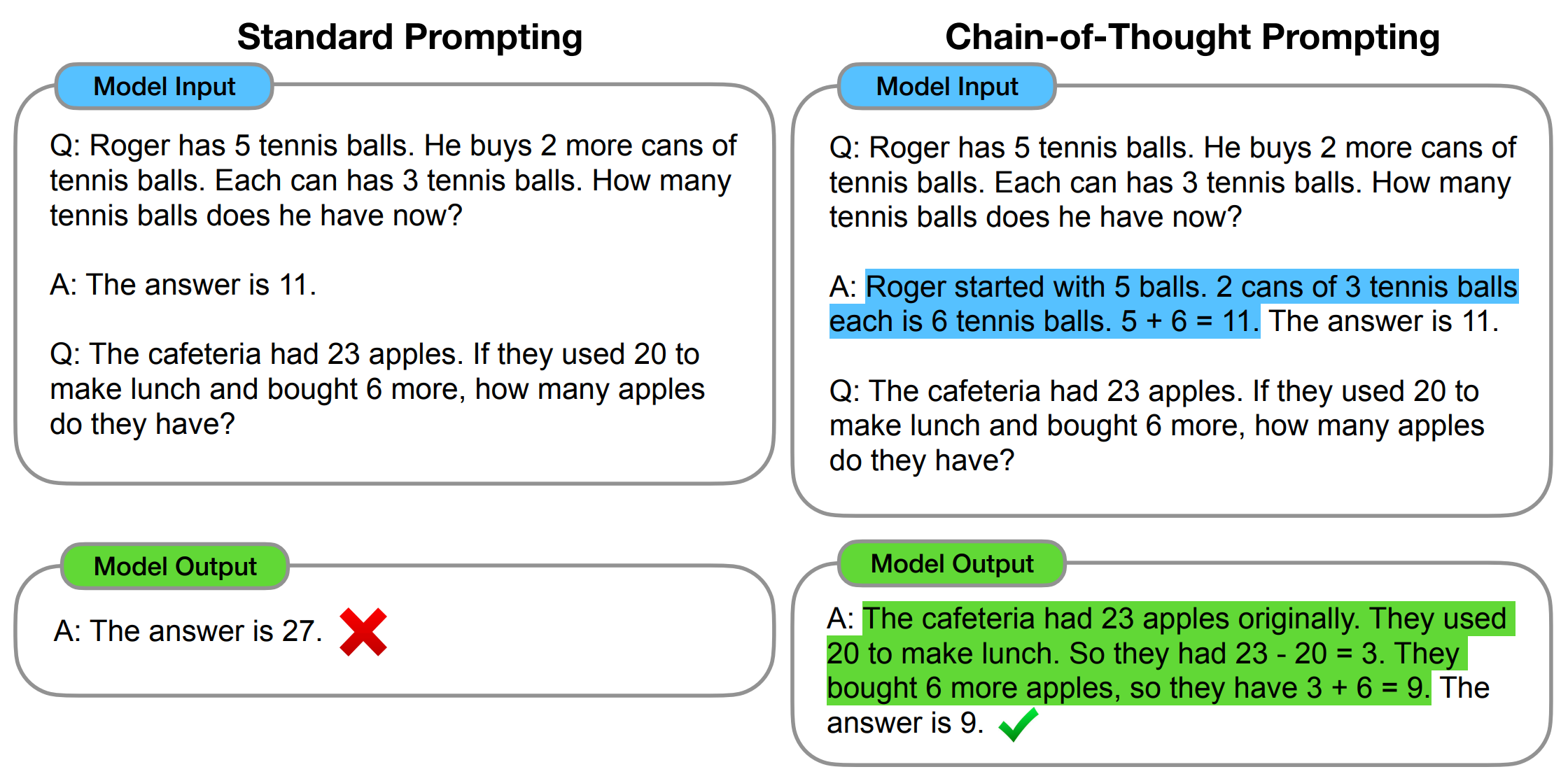
Figure 1: Illustration of the "chain-of-thought rationale" approach for solving an arithmetic word problem.
The paper “STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning”
Methodology
The authors propose a bootstraping approach to generate rationales for the training data. The rationale is generated by the LLM itself as shown in Figure 2. The rationale is generated by the LLM by using the following steps:
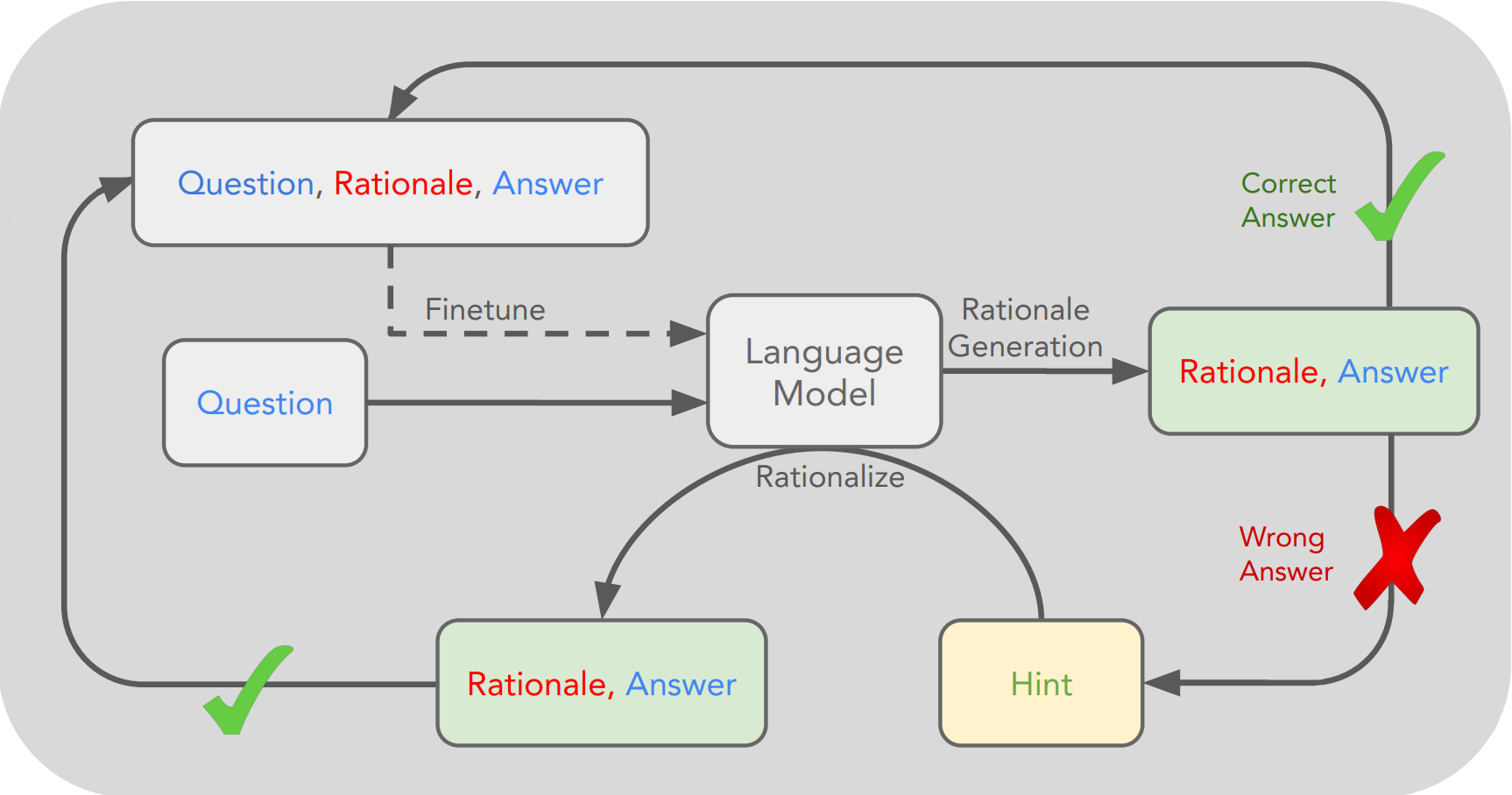
Figure 2: Illustration of the STaR algorithm.
- The LLM is given a few prompts with the question, rationale and answer.
- For each example in the training data, the LLM is given the question asked to generate the rationale and the answer.
- If the answer is correct then the rationale is added to the corresponding example in the training data.
- If the answer is wrong then the answer is given to the LLM along with the question in the prompt to generate a new rationale and answer. (Rationalize)
- Filter the examples that the LLm generated correct rationales for based on the ground truth answers.
- Fine-tune the LLM on the filtered examples.
- Repeat steps 2-6 until the maximum number of iterations is reached.
Results
The authors show that this approach is great for generating rationales from limited training data on a vriety of tasks.
Pros
- The approach is effective in generating rationales for complex reasoning tasks.
Cons
- The LLM sometimes generates rationales that are based on why the other answers are incorrect rather than why the correct answer is correct. Which may be due to the rationalization.
- GPT-3 variants like davinci’s performance is not shown. I think it will be the best among all the LLMs.