The ERIC system and its applications
A neurosymbolic framework, ERIC, that extracts rules from a CNN in the form of a decision tree is proposed by Townsend et al. Its application in covid-19 and pleural effusion detection is discussed.
Introduction
ERIC
Methodology
The rule extraction and inference pipeline is shown below in Figure 1.
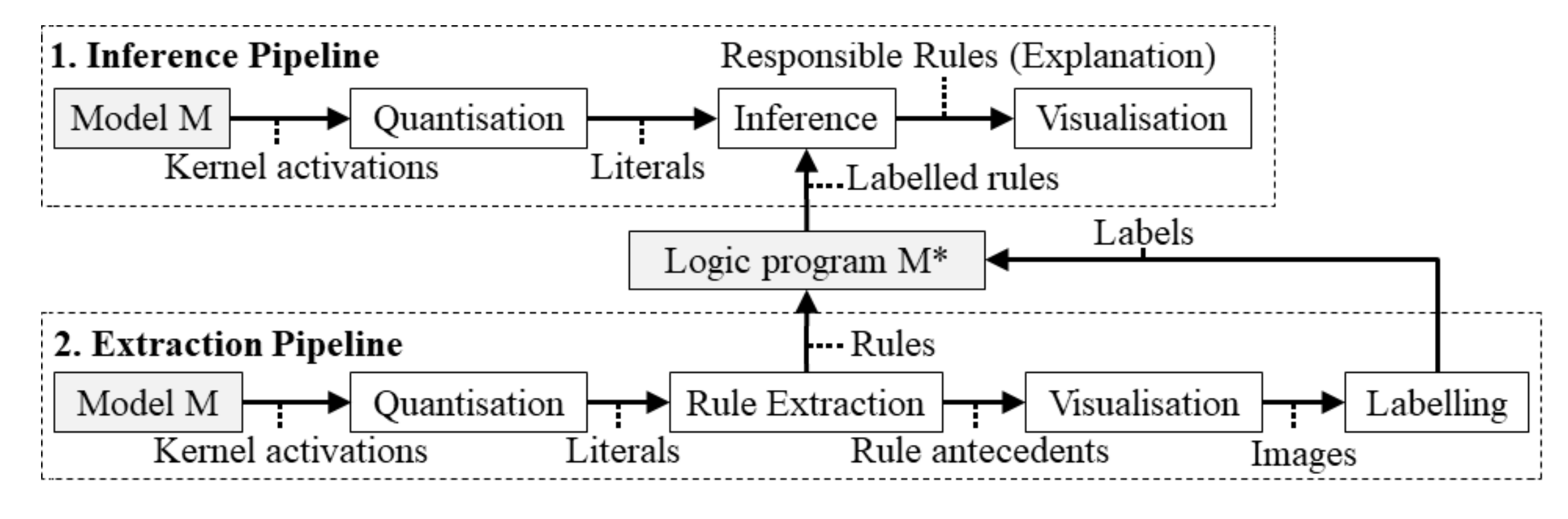
Figure 1: ERIC rule extraction and inference pipeline
Quantization
In the extraction pipeline the first step is to binarize the activations of the CNN filters. First, the norm of the last layer kernel activations are calculated. Then based on a threshold $\theta$, the outputs are binarized. The threshold is calculated as a weighted sum of the mean and standard deviation of norms of filter activations
Rule Extraction
The quantization step converts a subset of the training data into a 2D array of binary values, where a row represents an input image and a column represents a binarized filter activation. Now a simple decision tree learning algorithm like CART is used to extract a decision tree from this data.
Visualization and Labeling
The filters that appear in the rules are visualized and labeled by a human manually.
Inference
The inference is done by quantizing the last layer filters activations of the test input and using the decision tree to predict the class label.
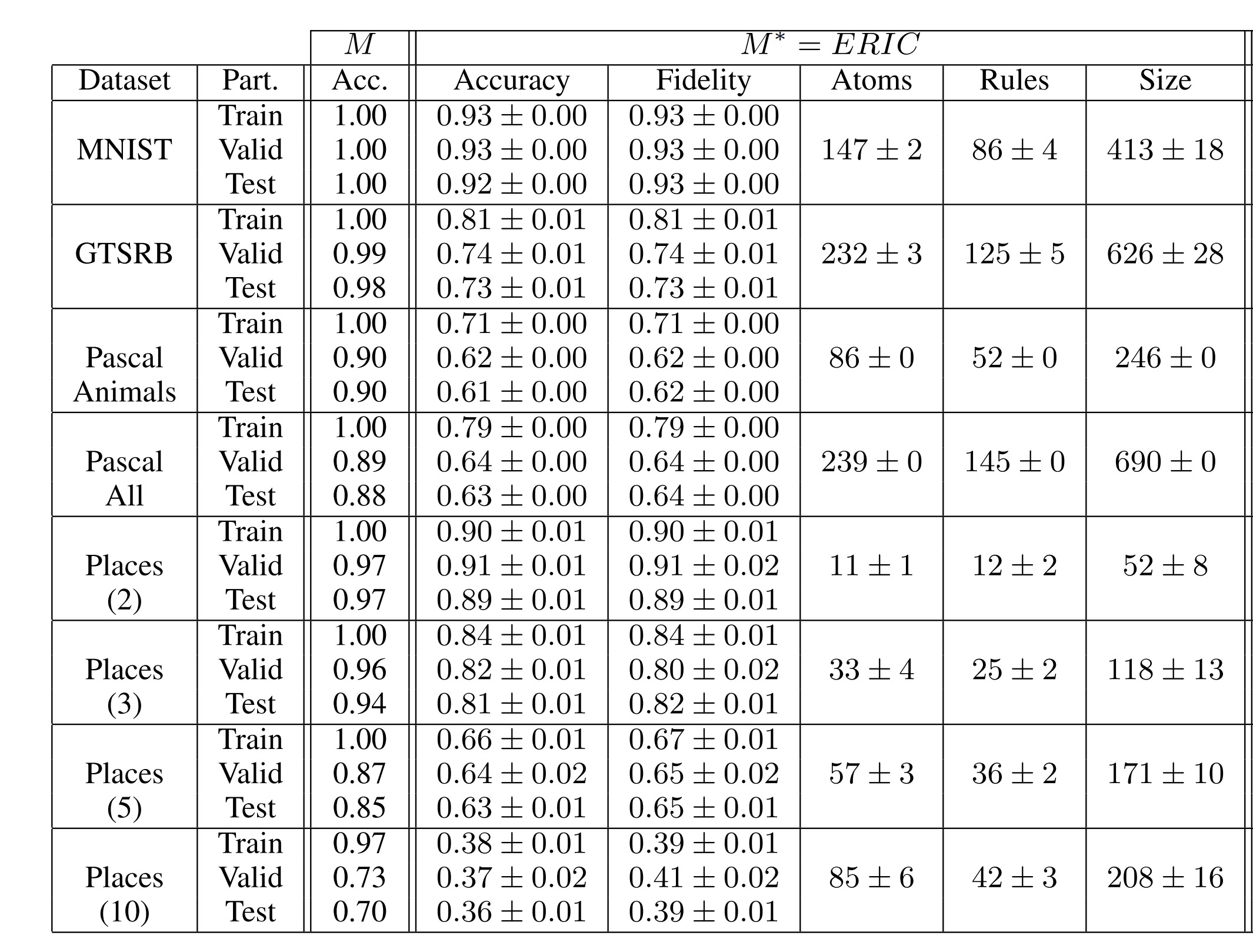
Figure 2: The performance of ERIC on different datasets
Improvements to ERIC
The authors also introduced a novel approach for propagating the gradients is used called Elite backpropagation
- Train the CNN on the dataset.
- Quantize the last layer filter activations of the training data.
- Find top-k filters that have the highest activation for each class (Elite filters)
- Train the CNN again with a loss function that penalizes the activation of non-elite filters.
- Obtain the trained CNN with more precise filters after training.
The idea is intuitive and it leads to better classification accuracy as well as better interpretability by virtue of sparse activation of filters. This seems to work better than a few other sparsity inducing methods that the authors compare against.
Applications
Ngan et al.